6장. 키-값 저장소 설계
- 키-값 저장소
- 키와 값을 쌍으로 저장하는 방식의 데이터베이스
- 비관계형 DB(NoSQL)의 일종
- 키를 통해 값을 빠르게 가져옴 (O(1))
- 키
- 고유한 식별자
- 값에 접근하게 해주는 역할
- 일반 텍스트(문자열) 혹은 해시 값
- 값
- 문자열, 리스트, 객체 등 다양한 타입
- Redis의 경우 키마다 값의 타입이 달라도 됨
- 예시
- Amazon DynamoDB
- Memcached
- Redis
- 이번 장의 설계 목표
- 다음 연산을 지원하는 키-값 저장소
- put(key, value): 키-값 쌍을 저장소에 저장
- get(key): 인자로 주어진 키에 매달린 값을 꺼냄
- 다음 연산을 지원하는 키-값 저장소
문제 이해 및 설계 범위 확장
- 설계 조건
- 키-값 쌍의 크기 10KB 이하
- 큰 데이터 저장 가능
- 높은 가용성 제공 (시스템에 장애가 있더라도 빠른 응답)
- 높은 규모 확장성 제공 (트래픽 양에 따라 자동으로 서버 증설/삭제)
- 데이터 일관성 수준 조정 가능
- 응답 지연시간(latency)이 짧아야 함
단일 서버 키-값 저장소
- 모든 데이터를 하나의 서버에 저장
- 장점: 간단한 설계
- 단점: 저장 공간이 제한적, 서버가 죽으면 사용 불가
분산 키-값 저장소
- 키-값 쌍을 여러 서버에 분산
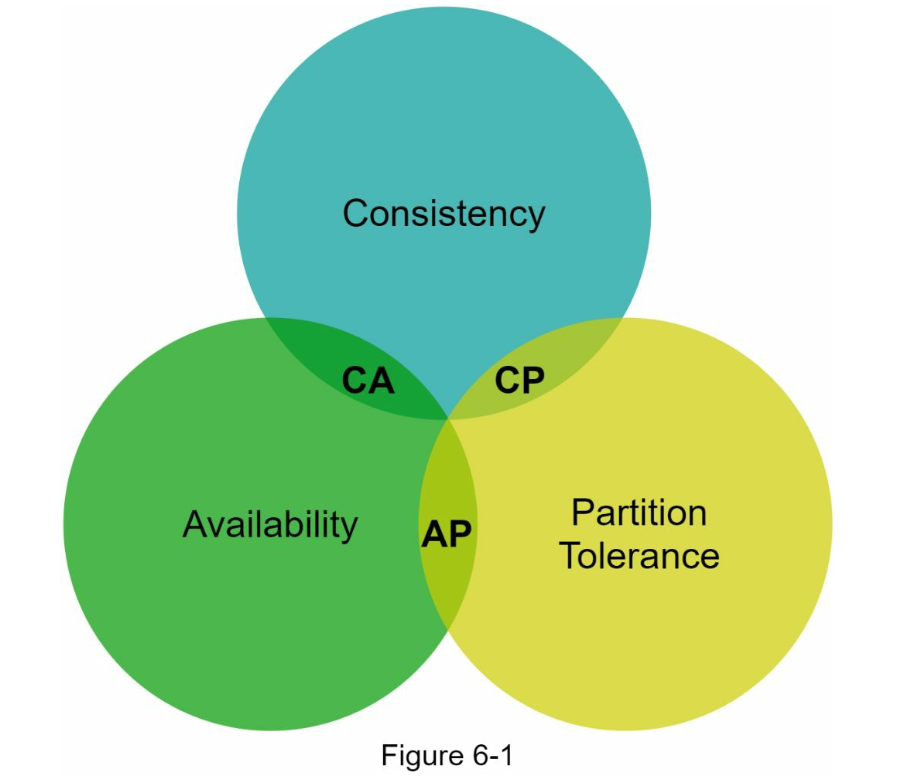
- CAP 정리
- 분산 시스템이 다음 세 가지 속성 모두를 만족하는 것은 불가
- 데이터 일관성
- 어떤 노드에서 읽어도 같은 값을 봄
- 가용성
- 일부 노드에 장애 발생시에도 항상 응답을 받을 수 있음
- 파티션 감내
- 네트워크가 끊겨도 시스템이 멈추지 않음
- 데이터 일관성
- 세 가지 요건 중 두 가지 요건을 만족하는 시스템을 아래와 같이 분류
- 분산 시스템이 다음 세 가지 속성 모두를 만족하는 것은 불가
-
-
- CP 시스템
- 일관성과 파티션 감내 지원, 가용성 희생
- AP 시스템
- 가용성과 파티션 감내 지원, 일관성 희생
- CA 시스템
- 일관성과 가용성 지원, 파티션 감내 희생
- 실제 사용시 분산 시스템은 반드시 파티션 감내를 지원해야하므로 실존하지 않음
- CP 시스템
- 이상적 상태
- 네트워크가 파티션되지 않음
- n1에 기록된 데이터는 자동으로 n2와 n3에 복제됨
- 데이터 일관성과 가용성을 만족
- 실세계의 분산 시스템
- 파티션 문제를 피할 수 없음
- CAP 정리에 따라 일관성과 가용성 중에 하나를 선택해야 하는 구조
- 예시: n3 서버에 파티션 문제가 발생
-

-
-
-
- 클라이언트가 n1이나 n2에 데이터를 기록한다면 n3에는 전달되지 않음
혹은 클라이언트가 n3에 데이터를 기록한다면 n1과 n2에 전달되지 않음 - 일관성을 선택한다면, 불일치 문제를 피하기 위해 쓰기 연산을 중단해야 하므로 가용성 깨짐
- 가용성을 선택한다면, 낡은 데이터를 반환할 위험이 있더라도 읽기/쓰기 연산을 지원
- 클라이언트가 n1이나 n2에 데이터를 기록한다면 n3에는 전달되지 않음
-
-
- 시스템 컴포넌트
- 키-값 저장소 구현에 사용될 핵심 컴포넌트들 및 기술들
- 데이터 파티션
- 데이터 다중화
- 일관성
- 일관성 불일치 해소
- 장애 처리
- 시스템 아키텍처 다이어그램
- 쓰기 경로
- 읽기 경로
- 참고
- Dynamo
- Cassandra
- BigTable
- 데이터 파티션
- 데이터를 작은 파티션들로 분할한 다음 여러 대의 서버에 저장 (sharding)
- 고려할 문제
- 데이터를 여러 서버에 고르게 분산
- 노드가 추가 되거나 삭제될 때 데이터 이동을 최소화
- 안정 해시로 이 문제를 풀 수 있음
- 규모 확장 자동화
- 시스템 부하에 따라 서버가 자동으로 추가되거나 삭제되게 할 수 있음
- 다양성
- 각 서버의 용량에 맞게 가상 노드의 수를 조정 가능 (고성능 서버는 더 많은 가상 노드를 갖도록 할 수 있음)
- 규모 확장 자동화
- 데이터 다중화
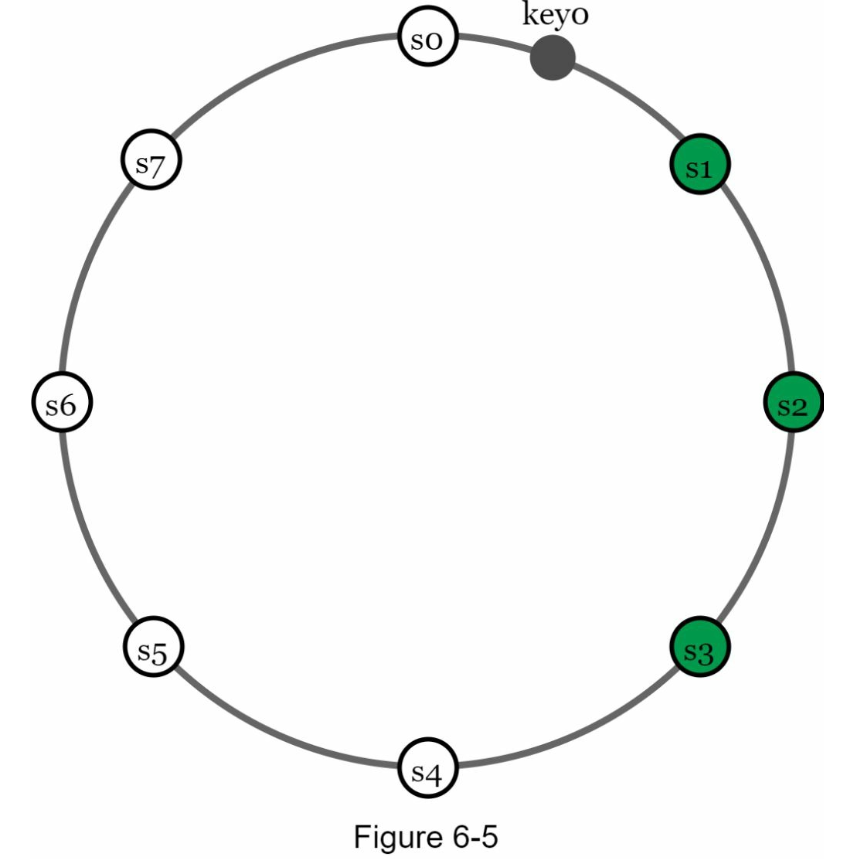
- 동일한 데이터를 N개 서버에 저장
- 어떤 키를 해시 링 위에 배치 후, 시계 방향으로 순회하며 만나는 첫 N개 서버에 데이터 사본을 저장
- 예시:
- 키-값 저장소 구현에 사용될 핵심 컴포넌트들 및 기술들
-
-
-
- N=3일 때 key0의 사본은 s1, s2, s3에 저장됨
- 주의할 점:
- 가상 노드를 사용하면 선택된 N개의 노드가 대응될 실제 물리 서버 개수가 N보다 작아질 수 있음
-> 노드 선택 시 물리 서버를 중복 선택하지 않도록 해야 함 - 동일한 데이터 센터에 속한 노드는 정전, 네트워크 이슈, 자연재해 등의 문제를 동시에 겪을 수 있음
-> 안정성을 위해 데이터 사본을 다른 데이터 센터의 서버에 보관
- 가상 노드를 사용하면 선택된 N개의 노드가 대응될 실제 물리 서버 개수가 N보다 작아질 수 있음
-
-
- 데이터 일관성
- 여러 노드에 다중화된 데이터를 동기화해야 함
- 정족수 합의 프로토콜
- 읽기/쓰기 연산 모두에 일관성을 보장
- 정의
- N = 사본 개수
- W = 쓰기 연산에 필요한 최소 응답 수
- R = 읽기 연산에 필요한 최소 응답 수
- 예시:

-
-
-
- N=3이고 데이터가 s0, s1, s2에 다중화
- W=1 이라면 한대 이상의 서버로부터 쓰기 성공 응답을 받으면 쓰기 연산이 성공했다고 판단
- 중재자: 클라이언트 요청을 받아 여러 노드에 전달하고, 응답을 수집하여 최종 결과를 결정하는 중앙 역할을 함
- N, W, R을 정하는 법
- W, R 값이 작으면 응답 속도가 올라가지만 일관성이 떨어짐
- W, R 값이 크면 응답 속도는 느려지지만 일관성이 향상됨
- 예시:
- R = 1, W = N: 빠른 읽기 연산에 최적화된 시스템
- W = 1, R = N: 빠른 쓰기 연산에 최적화된 시스템
- W + R > N : 강한 일관성이 보장됨 (보통 N=3, W=R=2)
- W + R <= N : 강한 일관성이 보장되지 않음
-
-
- 일관성 모델
- 데이터 일관성의 수준을 결정하는 모델
- 강한 일관성: 모든 읽기 연산은 가장 최근에 갱신된 결과를 반환
- 현재 쓰기 연산의 결과가 반영될 때까지 모든 사본에서 해당 데이터 대한 읽기/쓰기를 금지
- 고가용성 시스템에 부적합
- 약한 일관성: 읽기 연산은 가장 최근에 갱신된 결과를 반환하지 못할 수 있음
- 결과적 일관성: 약한 일관성의 일종으로, 갱신 결과가 결국에는 모든 사본에 반영됨
- 고가용성 시스템에 적합
- 쓰기 연산이 병렬적으로 발생하면 일관성이 깨질 수 있음 -> 클라이언트가 해결해야 함
- 비 일관성 해소 기법: 데이터 버저닝
- 버저닝과 벡터 시계로 데이터 다중화의 일관성 문제를 해소
- 버저닝:
- 데이터를 변경할 때마다 데이터의 새로운 버전을 생성
- 각 버전의 데이터는 immutable
- 예제:

-
-
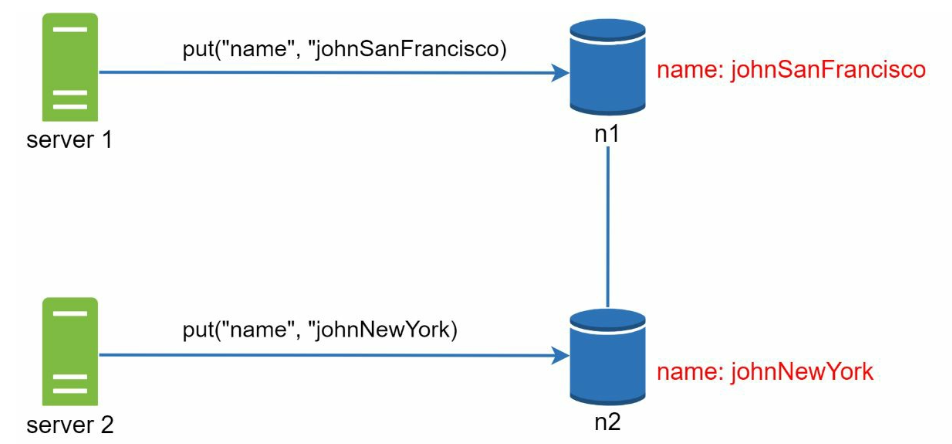
- 어떤 데이터의 사본이 n1, n2에 보관되어 있음
- 서버1, 서버2가 이 데이터를 가져오려는 상황
-
-
-
- 서버1과 서버2가 name을 서로 다른 값으로 동시에 변경
- 원래 값 John은 버저닝으로 무시됨
- 충돌 발생은 해결할 수 없음 -> 벡터 시계 사용
- 벡터 시계:
- [서버, 버전] 순서쌍을 데이터에 매단 것
- 버전이 선행인지, 후행인지, 충돌이 있는지 판별하는 데 사용됨
- D=데이터, vi= 버전 카운터, Si는 서버 번호일 때 D([S1, v1], [S2, v2], ..., [Sn, vn]) 꼴로 표현
- D를 서버 Si에 기록하면 아래 중 하나를 수행
- [Si, vi]가 있으면 vi를 증가시킴
- 그렇지 않으면 새 항목 [Si, 1]를 만듦
- 사례:
-
-
-
-
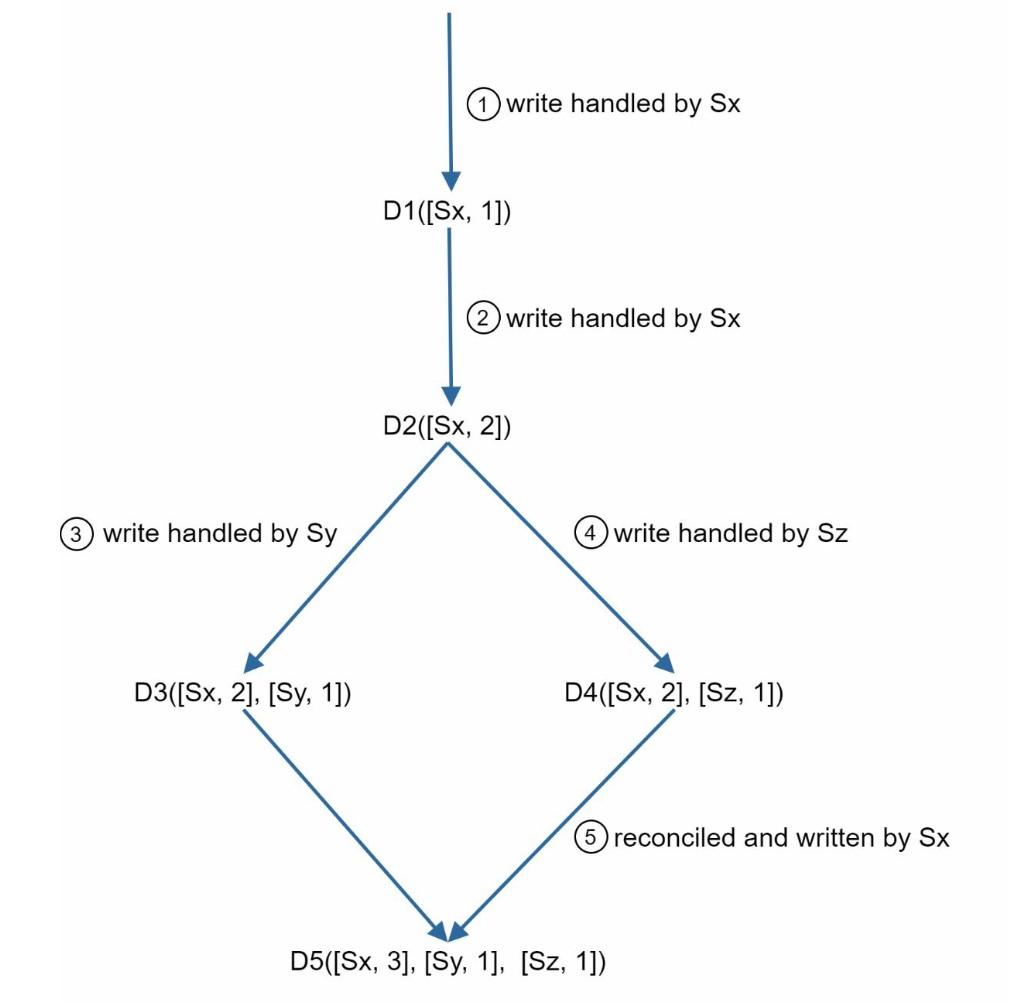
- 클라이언트가 D1을 시스템에 기록, Sx 서버가 이를 처리
-> 벡터 시계: D1([Sx, 1]) - 다른 클라이언트가 D1을 읽고 D2로 업데이트 하여 기록 (D2가 D1을 덮어 씀), Sx 서버가 처리
-> 벡터 시계: D2([Sx, 2]) - 다른 클라이언트가 D2를 읽고 D3로 업데이트 하여 기록, Sy가 처리
-> 벡터 시계: D3([Sx, 2], [Sy, 1]) - 다른 클라이언트가 D2를 읽고 D4로 업데이트 하여 기록, Sz가 처리
-> 벡터 시계: D4([Sx, 2], [Sz, 1]) - 어떤 클라이언트가 D3과 D4를 읽으면 충돌 발생을 인지 (D2를 Sy와 Sz가 서로 다른 값으로 바꿈)
-> 클라이언트가 해소 후 서버에 기록, Sx가 처리
-> 벡터 시계: D4([Sx, 3], [Sy, 1], [Sz, 1])
(W >= 2 인 경우에.. D3, D4를 둘 다 읽게되면 인지 가능할듯)
- 클라이언트가 D1을 시스템에 기록, Sx 서버가 이를 처리
- 단점:
- 충돌 감지 및 해소 로직이 클라이언트에 들어가야 하므로 클라이언트가 복잡해짐
- 순서쌍 개수가 빠르게 늘어나기 때문에 임계치 이상으로 길이가 길어지면 오래된 순서쌍을 제거하는 로직이 필요
-> 버전 간 선후 관계 정보를 손실하여 충돌 해소 과정의 효율성이 낮아짐
-> 실제 서비스에서는 이런 문제가 발생하지 않음
-
-
- 장애 처리
- 대규모 시스템에서 장애는 흔하고, 어떻게 처리할지는 중요한 문제
- 장애 감지:
- 분산 시스템에서는 보통 두 대 이상의 서버가 어떤 서버의 장애를 보고하면 실제로 해당 서버에 장애가 발생했다고 간주
- 멀티캐스팅:
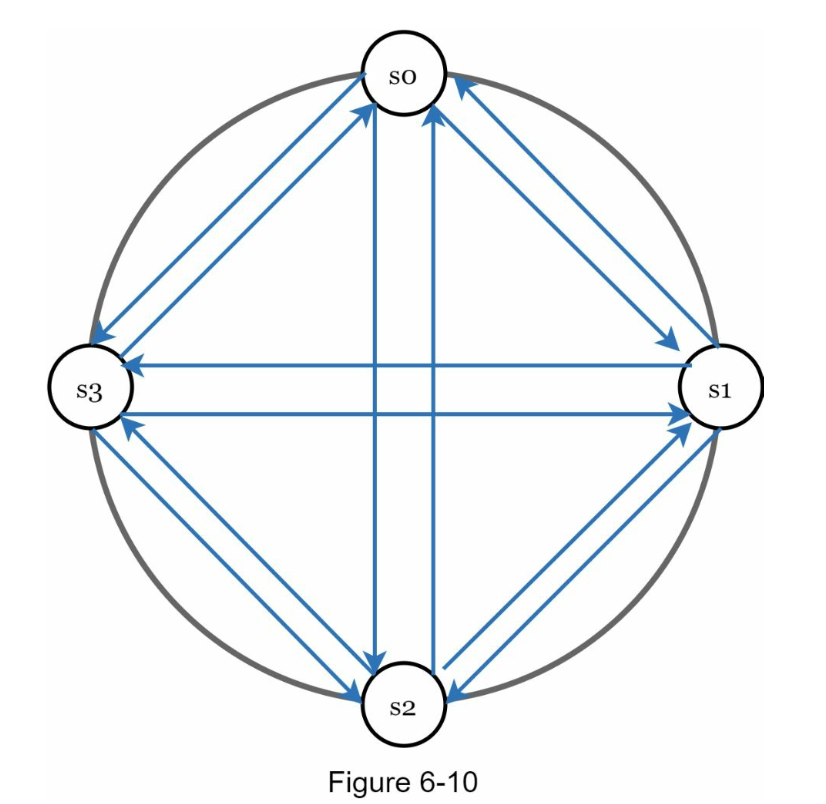
-
-
-
- 장애를 감지하는 가장 손쉬운 방법이지만, 서버가 많을 때는 비효율적
- 가십 프로토콜:
- 동작 원리:
- 각 노드는 멤버 id와 그 박동 카운터 쌍을 저장하는 멤버십 목록을 유지
- 각 노드는 주기적으로 자신의 박동 카운터를 증가
- 각 노드는 무작위로 선정된 노드들에게 주기적으로 자신의 박동 카운터 목록을 전송
- 박동 카운터 목록을 받은 노드는 멤버십 목록을 갱신
- 어떤 멤버의 박동 카운터 값이 지정된 시간 동안 갱신되지 않으면 그 멤버를 장애 상태로 간주
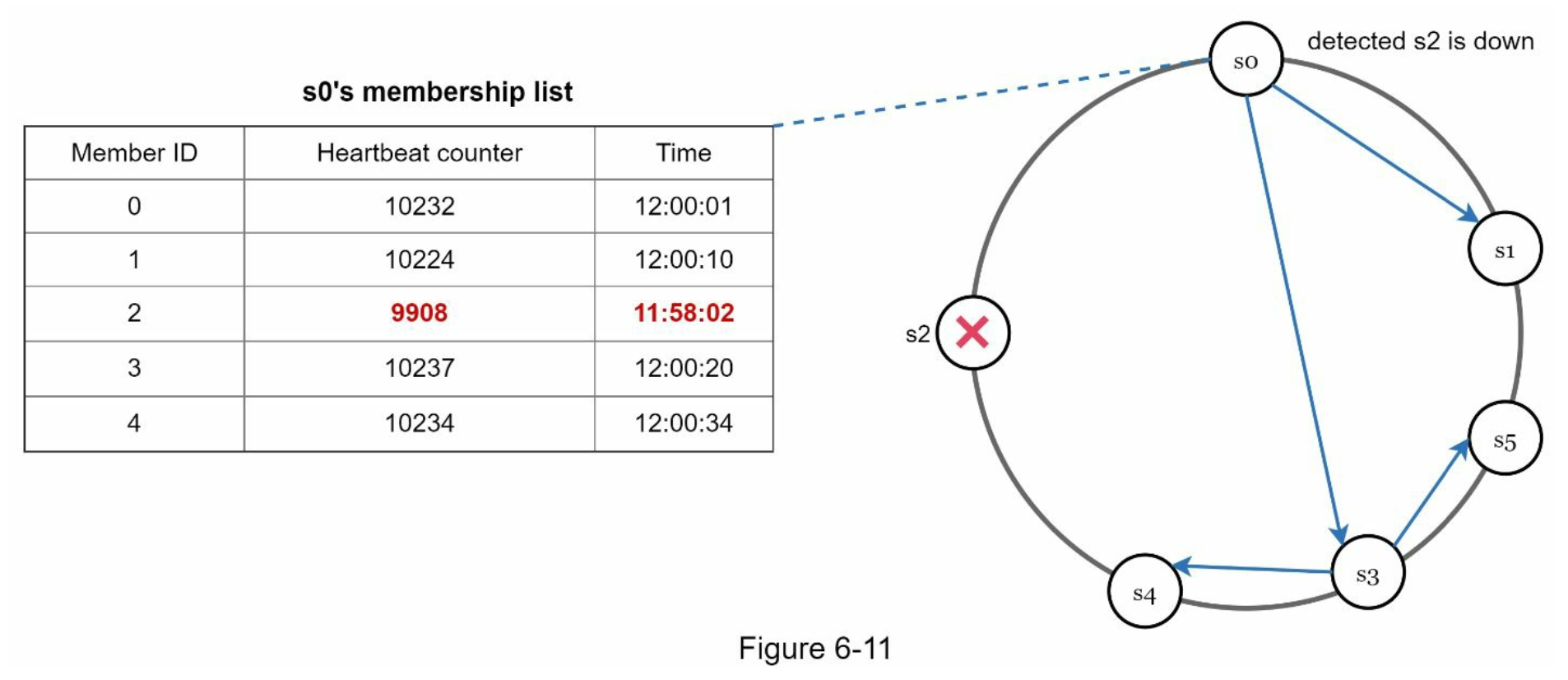
- 예제:
- 동작 원리:
-
-
-
-
-
-
- 좌측 테이블은 노드 s0의 멤버십 목록
- 노드 s0이 노드 멤버인 s2의 박동 카운터가 오랫동안 증가하지 않은 것을 발견
- 노드 s0은 노드 s2을 포함하는 박동 카운터 목록을 무작위로 선택된 다른 노드들에 전달
- 노드 s2의 박동 카운터가 오랫동안 증가되지 않았음을 발견한 모든 노드는 해당 노드를 장애 노드로 표시
-
-
- 일시적 장애 처리
- 가십 프로토콜로 장애를 감지한 시스템은 가용성을 보장하기 위한 조치를 취해야 함
- 느슨한 정족수 접근법으로 가용성을 높일 수 있음
- 읽기와 쓰기 연산을 금지하지는 않지만, 정족수 요구사항을 강제함
- 해시링에서 쓰기 연산을 수행할 W개의 정상 서버와 읽기 연산을 수행할 R개의 정상 서버를 고름
- 장애 상태인 서버로 가는 요청은 다른 서버가 잠시 맡아서 처리하고, 서버가 복구되었을 때 일괄 반영
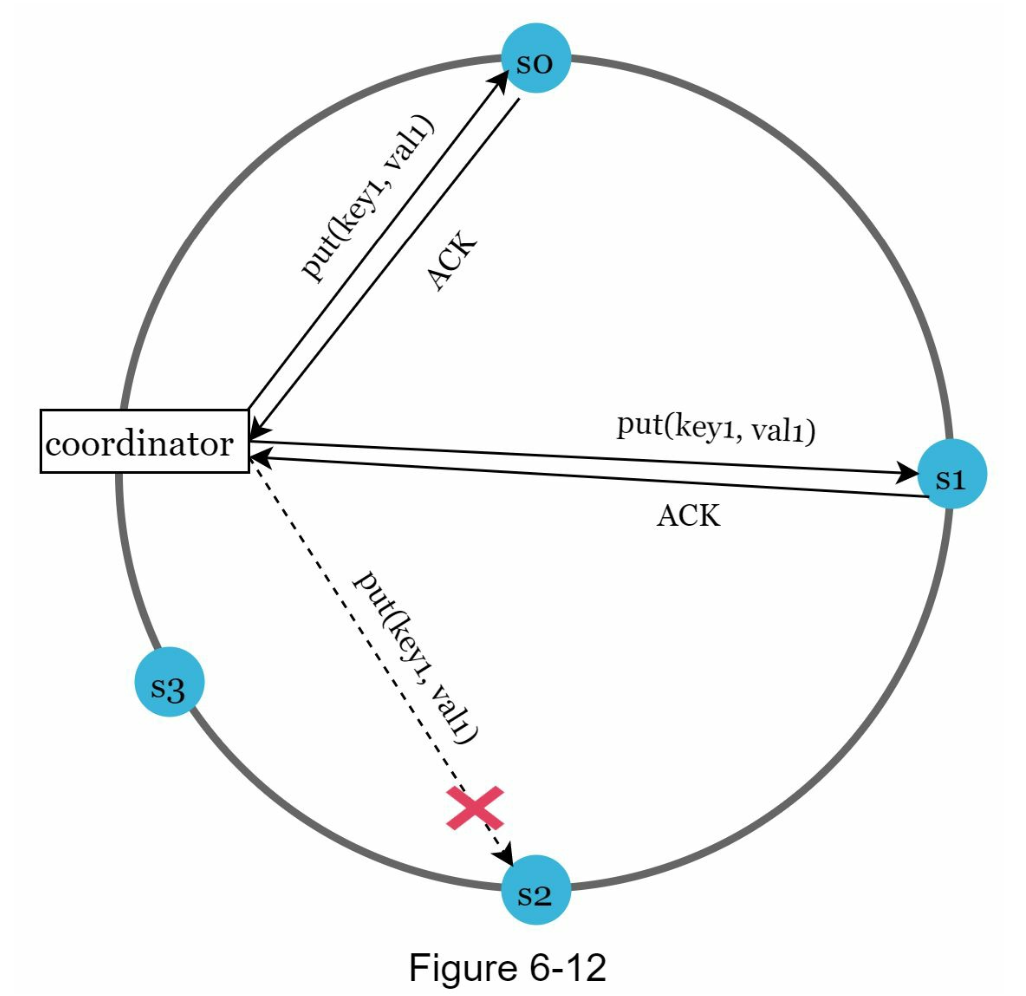
이를 위해 임시로 쓰기 연산을 처리한 서버에는 단서를 남겨둠 (단서 후 임시 위탁법) - 예제:
-
-
-
-
-
- 장애 상태인 s2에 대한 읽기/쓰기 연산은 노드 s3가 처리
- s2가 복구되면 s3은 갱신된 데이터를 s2로 인계
-
-
- 영구 장애 처리
- 반-엔트로피 프로토콜:
- 영구적인 노드의 장애를 처리
- 사본들을 비교하여 최신 버전으로 갱신하는 과정을 포함
- 머클 트리를 사용하여 사본 간의 일관성이 망가진 상태를 탐지하고 전송 데이터의 양을 줄임
- 예제:
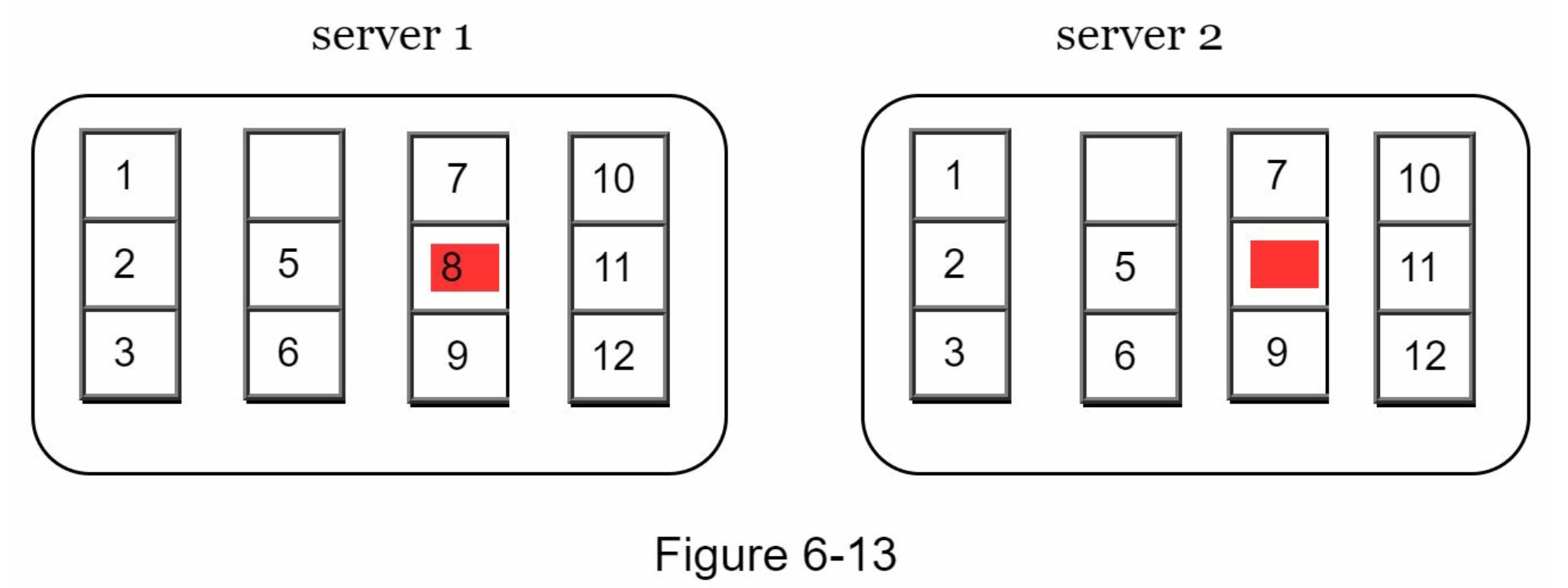
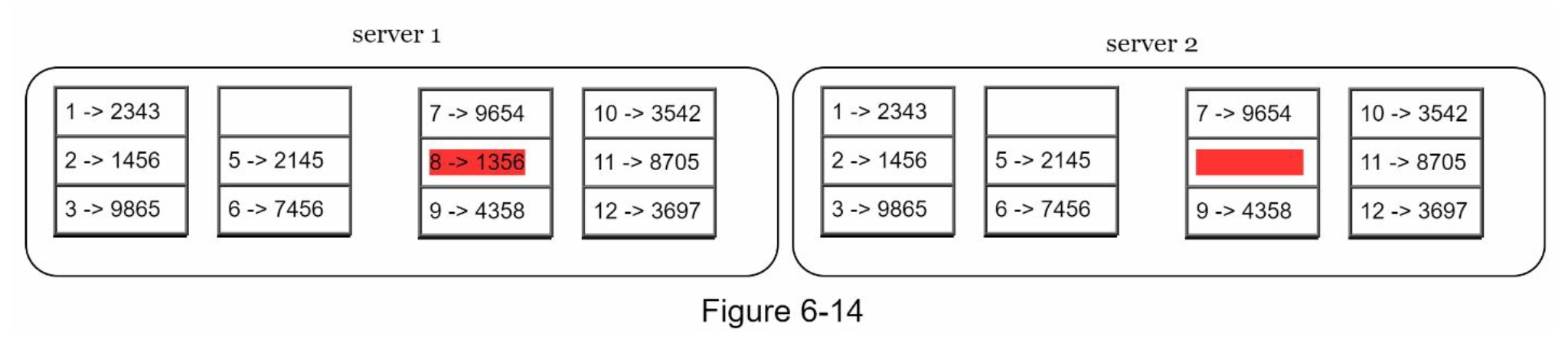
- 키 공간이 1부터 12까지일 때 머클 트리 생성
- 일관성이 깨진 데이터가 있는 상자는 빨간색으로 표시
- 반-엔트로피 프로토콜:
-

-
-
-
-
- 키 공간을 버킷으로 나눔 (그림에서는 4개 버킷)
- 버킷에 포함된 각 키에 균등 분포 해시 함수를 적용하여 해시 값을 계산
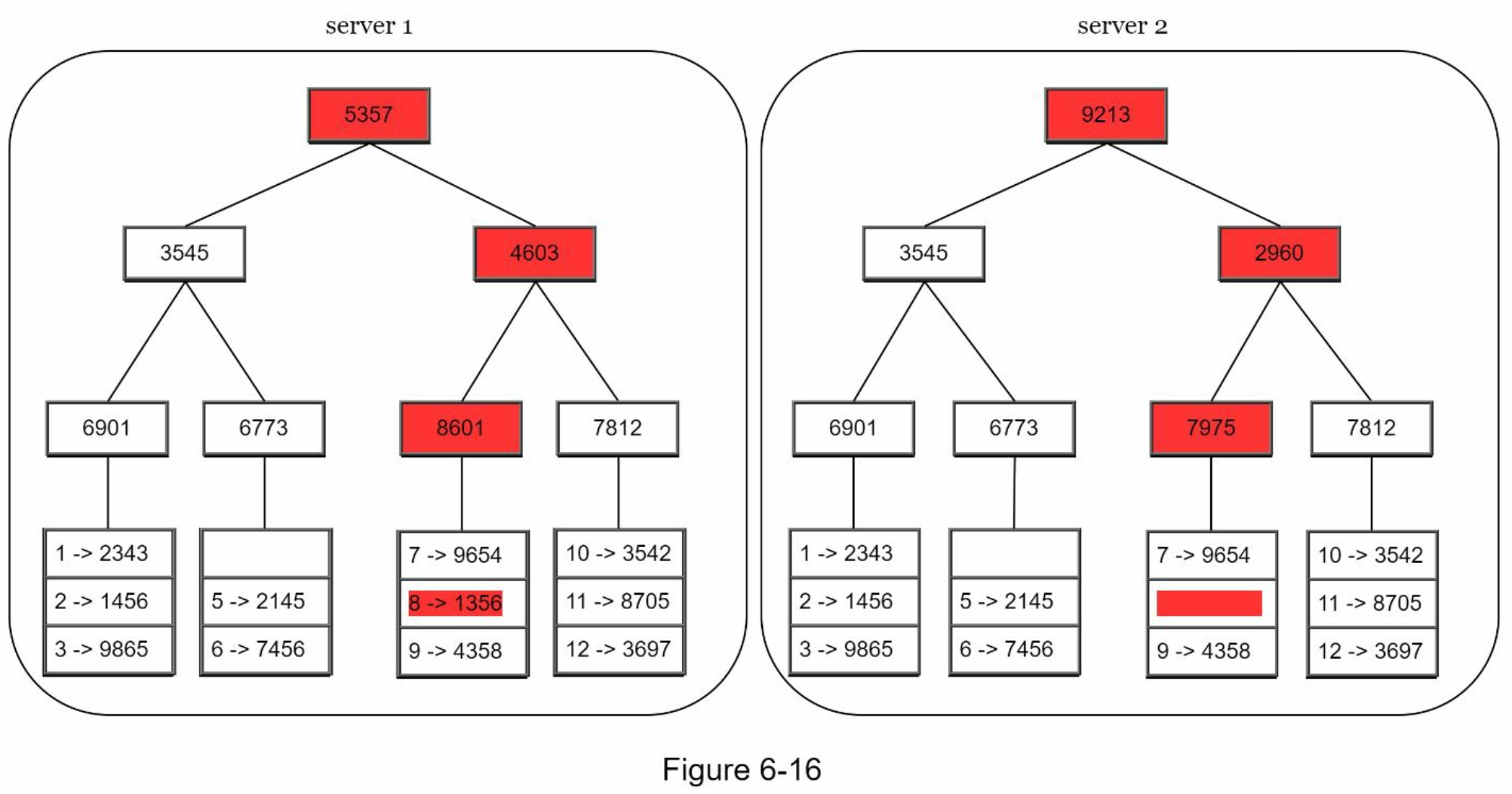
- 버킷별로 해시값 계산 후, 해당 해시 값을 레이블로 갖는 노드 생성
- 자식 노드의 레이블로부터 새로운 해시 값을 계산하여 이진 트리를 상향식으로 구성
- 두 머클 트리를 비교할 때는 루트 노드의 해시값을 비교하여,
- 일치하면 두 서버는 같은 데이터를 갖는 것
- 다르면 자식 노드를 탐색하여 다른 데이터를 갖는 버킷을 찾아 동기화 (DFS인듯)
- 실제로 쓰이는 시스템의 경우 버킷 하나의 크기가 큼
- 10억 개의 키를 백만 개의 버킷으로 관리하는 경우, 하나의 버킷은 1000개의 키를 관리
-
-
- 시스템 아키텍처 다이어그램
- 예제:
-

-
-
-
- 클라이언트는 get(key) 및 put(key, value) 두 가지 단순한 API와 통신
- 중재자는 클라이언트에게 키-값 저장소에 대한 프락시 역할
- 노드는 안정 해시의 해시 링 위에 분포
- 노드를 자동으로 추가 또는 삭제할 수 있도록 시스템은 완전히 분산
- 데이터는 여러 노드에 다중화
- 모든 노드가 같은 책임을 지므로 SPOF는 존재하지 않음
- 완전히 분산된 설계를 채택하였으므로 모든 노드가 아래 기능 전부를 지원해야 함
-
-

-
- 쓰기 경로
- 카산드라의 사례를 참조하여 쓰기 요청을 구조화하면 아래와 같음
- 쓰기 경로

-
-
-
- 쓰기 요청이 커밋 로그에 기록됨
- 데이터가 메모리 캐시에 기록됨
- 메모리 캐시가 가득차거나 임계치에 도달하면 데이터는 디스크의 SSTable(Sorted-String Table)에 기록됨
SSTable은 <키, 값> 순서쌍을 정렬된 리스트 형태로 관리
-
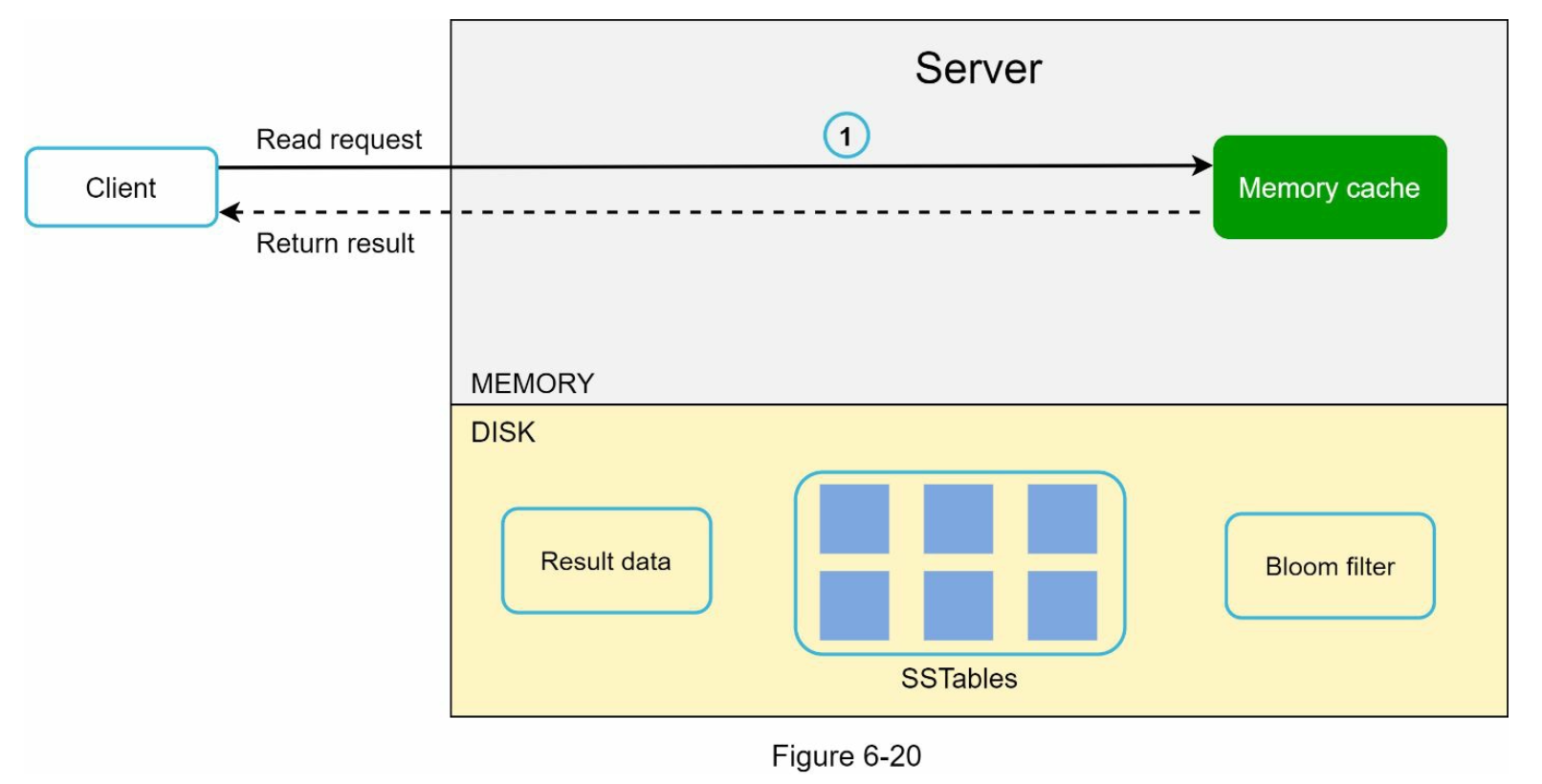
- 읽기 경로
-
-
-
- 읽기 요청을 받은 노드는 데이터가 메모리 캐시에 있는지 살피고 있으면 데이터를 클라이언트에 반환
-

-
-
- 없으면 디스크에서 가져옴
- 찾는 키가 어느 SSTable에 있는지 효율적으로 알아내기 위해 블룸 필터를 사용
- 데이터가 메모리에 있는지 검사하고 없으면 2로 감
- 데이터가 메모리에 없으므로 블룸 필터 검사
- 블룸 필터를 통해 어떤 SSTable에 키가 보관되어 있는지 알아냄
- SSTable에서 데이터를 가져옴
- 해당 데이터를 클라이언트에 반환
-
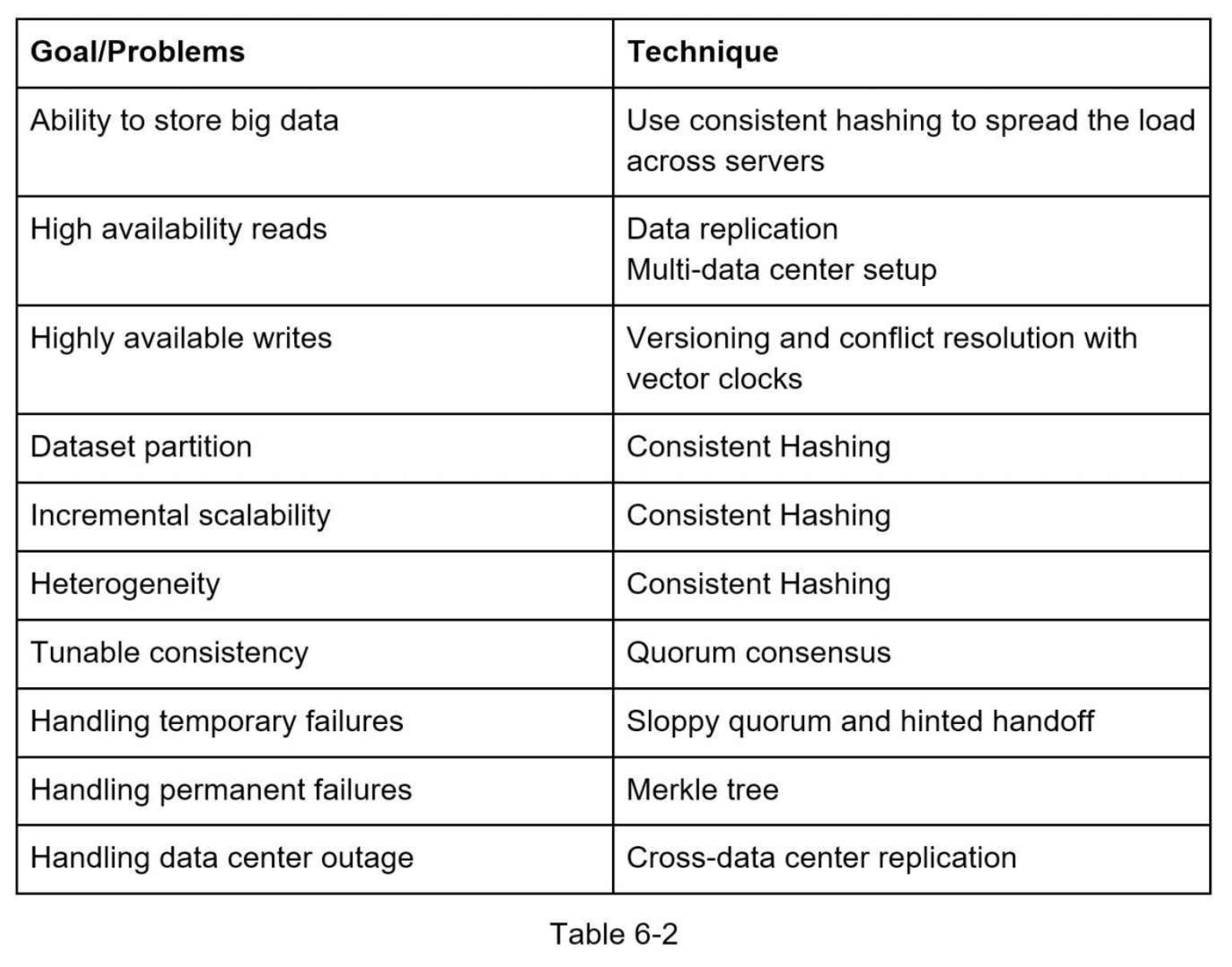
요약
'대규모 시스템 설계 기초' 카테고리의 다른 글
| 대규모 시스템 설계 기초 - 10장 (0) | 2025.04.12 |
|---|---|
| 대규모 시스템 설계 기초 - 9장 (0) | 2025.04.12 |
| 대규모 시스템 설계 기초 - 8장 (1) | 2025.04.06 |
| 대규모 시스템 설계 기초 - 7장 (1) | 2025.04.06 |
| 대규모 시스템 설계 기초 - 5장 (1) | 2025.03.30 |



